 |
MIDAPACK - MIcrowave Data Analysis PACKage
1.1b
Parallel software tools for high performance CMB DA analysis
|
|
MIDAPACK - MIcrowave Data Analysis PACKage
1.1b
Parallel software tools for high performance CMB DA analysis
|
In the memory-distributed (MPI) running modes, the data input matrix is assumed to be distributed in between the MPI processes (nodes, processors, etc). The library routines allow essentially for two different data distributions as well as one inermediate option.
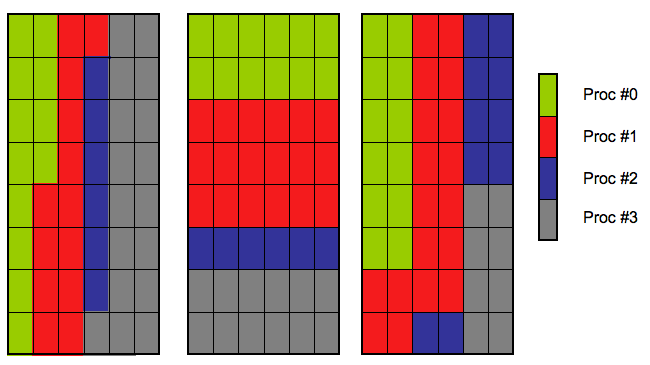
column-wise, row-wise, and hybrid (with k = 2) distribution.The first distribution is called hereafter a column-wise distribution. In this case the data matrix is treated as a vector made of columns of the data matrix concatenated together. A valid data distribution can be then nearly any partition of the vector into consecutive segments, which are then assigned one-by-one to the processes. It is then assumed that the neighboring processes receive consecutive segments. Moreover, each process has to have at least as many data points as a half-bandwith of a Toeplitz block corresponding to them, if it has only one Toeplitz block assigned, which does not start or end within the data ranges.
The second distribution is called hereafter a row-wise distribution and it corresponds to dividing the data matrix into subblocks with a number of columns as in the full matrix. This time neighboring processess have to have blocks corresponding to the consecutive rows of the data matrix and each process has to have at least as many rows as the band-width of the corresponding Toeplitz blocks, unless one of the Toeplitz blocks assigned to that set of rows starts or end within the rows interval.
The hybrid data distribution first represents the data matrix as a matrix of 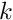 columns, where
columns, where 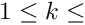 # of columns of the data matrix. This is obtained by concatenating first columns of the data matrix, by following
# of columns of the data matrix. This is obtained by concatenating first columns of the data matrix, by following  etc ... - note that the total number of columns of the data matrix has to divide by - and then chopping such a matrix into segments assigned to different MPI process. The requirements as above also apply.
etc ... - note that the total number of columns of the data matrix has to divide by - and then chopping such a matrix into segments assigned to different MPI process. The requirements as above also apply.
What data layout is used is defined by the input parameters of the MPI routines.
For all the routines of the package, the layout of the output coincides with that of the input.