 |
MIDAPACK - MIcrowave Data Analysis PACKage
1.1b
Parallel software tools for high performance CMB DA analysis
|
|
MIDAPACK - MIcrowave Data Analysis PACKage
1.1b
Parallel software tools for high performance CMB DA analysis
|
Here is an application example of a least square problem resolution which is implemented in test_pcg_mapmat.c . Considering a problem formulated as 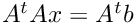 , Solution x can be compute iteratively using conjutgate gradient. Instead computing and storing the whole
, Solution x can be compute iteratively using conjutgate gradient. Instead computing and storing the whole 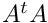 matrix, we apply succesively pointing,
matrix, we apply succesively pointing, 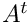 , and unpointing products,
, and unpointing products, 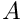 , at each iterate.
, at each iterate.
Classic gradient conjugate algorithm has been slightly modified. As we explain and are applied succesively. Furtherwise dotproduct operations in the overlapped domain have been moved in the distributed domain. Espacially we use relation : 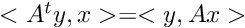 .
.
Algorithm needs into memory 6 vectors :
Complexity, counting operations at each iterate, is detailled as follow :
(no communication), (communication = MIDAPACK Communication scheme).More information about pointing operator are detailled, in the pointing function synposis